Download raw body.
SoftLRO for ixl(4), bnxt(4) and em(4)
From: Yuichiro NAITO <naito.yuichiro@gmail.com>
Subject: Re: SoftLRO for ixl(4), bnxt(4) and em(4)
Date: Fri, 07 Mar 2025 17:34:22 +0900 (JST)
> From: Jan Klemkow <j.klemkow@wemelug.de>
> Subject: Re: SoftLRO for ixl(4), bnxt(4) and em(4)
> Date: Tue, 4 Mar 2025 20:02:31 +0100
>
>> On Fri, Nov 15, 2024 at 11:30:08AM GMT, Jan Klemkow wrote:
>>> On Thu, Nov 07, 2024 at 11:30:26AM GMT, David Gwynne wrote:
>>> > On Thu, Nov 07, 2024 at 01:10:10AM +0100, Jan Klemkow wrote:
>>> > > This diff introduces a software solution for TCP Large Receive Offload
>>> > > (SoftLRO) for network interfaces don't hat hardware support for it.
>>> > > This is needes at least for newer Intel interfaces as their
>>> > > documentation said that LRO a.k.a. Receive Side Coalescing (RSC) has to
>>> > > be done by software.
>>> > > This diff coalesces TCP segments during the receive interrupt before
>>> > > queueing them. Thus, our TCP/IP stack has to process less packet
>>> > > headers per amount of received data.
>>> > >
>>> > > I measured receiving performance with Intel XXV710 25 GbE interfaces.
>>> > > It increased from 6 Gbit/s to 23 Gbit/s.
>>> > >
>>> > > Even if we saturate em(4) without any of these technique its also part
>>> > > this diff. I'm interested if this diff helps to reach 1 Gbit/s on old
>>> > > or slow hardware.
>>> > >
>>> > > I also add bnxt(4) to this diff to increase test coverage. If you want
>>> > > to tests this implementation with your favorite interface, just replace
>>> > > the ml_enqueue() call with the new tcp_softlro_enqueue() (as seen
>>> > > below). It should work with all kind network interfaces.
>>> > >
>>> > > Any comments and tests reports are welcome.
>>> >
>>> > nice.
>>> >
>>> > i would argue this should be ether_softlro_enqueue and put in
>>> > if_ethersubr.c because it's specific to ethernet interfaces. we don't
>>> > really have any other type of interface that bundles reception of
>>> > packets that we can take advantage of like this, and internally it
>>> > assumes it's pulling ethernet packets apart.
>>> >
>>> > aside from that, just a few comments on the code.
>>>
>>> I adapted your comments in the diff below.
>>
>> I refactored the SoftLRO diff. You just need to add the flags IFXF_LRO
>> / IFCAP_LRO, and repalce ml_enqueue() with tcp_softlro_enqueue() to
>> enable this on you favorit network device.
>>
>> Janne: I adjusted your diff with correct headers. But, I'm unable to
>> test this part of the diff below, due to lack of hardware. Could you
>> test it again?
>>
>> Yuichiro: Could you also retest your UDP/TCP forwarding test? I added a
>> short path for non-TCP packets in the ixl(4) driver. Maybe its better
>> now.
>
> Thanks for your latest patch. It improves the ipgen test with 2 ixl(4) nics.
> It looks very good performance shown as below.
>
> ```
> rfc2544 tolerable error rate: 0.0000%
> rfc2544 trial duration: 10 sec
> rfc2544 pps resolution: 0.0000%
> rfc2544 interval: 0 sec
> rfc2544 warming duration: 1 sec
>
> framesize|0G 1G 2G 3G 4G 5G 6G 7G 8G 9G 10Gbps
> ---------+----+----+----+----+----+----+----+----+----+----+
> 64 |#### 623.96Mbps, 1218672/14880952pps, 8.19%
> 128 |####### 1249.54Mbps, 1220252/ 8445945pps, 14.45%
> 512 |######################### 4813.20Mbps, 1175098/ 2349624pps, 50.01%
> 1024 |################################################# 9771.27Mbps, 1192782/ 1197318pps, 99.62%
> 1280 |################################################## 9845.54Mbps, 961479/ 961538pps, 99.99%
> 1408 |################################################## 9859.94Mbps, 875350/ 875350pps, 100.00%
> 1518 |################################################## 9869.91Mbps, 812740/ 812743pps, 100.00%
>
> framesize|0 |1m |2m |3m |4m |5m |6m |7m |8m |9m |10m |11m |12m |13m |14m |15m pps
> ---------+----+----+----+----+----+----+----+----+----+----+----+----+----+----+----+
> 64 |###### 1218672/14880952pps, 8.19%
> 128 |###### 1220252/ 8445945pps, 14.45%
> 512 |##### 1175098/ 2349624pps, 50.01%
> 1024 |##### 1192782/ 1197318pps, 99.62%
> 1280 |#### 961479/ 961538pps, 99.99%
> 1408 |#### 875350/ 875350pps, 100.00%
> 1518 |#### 812740/ 812743pps, 100.00%
> ```
>
> However TCP forwarding performance looks the same as the first patch.
>
> ```
> # iperf3 -c 192.168.200.10
> Connecting to host 192.168.200.10, port 5201
> [ 5] local 192.168.100.10 port 19800 connected to 192.168.200.10 port 5201
> [ ID] Interval Transfer Bitrate Retr Cwnd
> [ 5] 0.00-1.00 sec 343 MBytes 2.87 Gbits/sec 75 1.04 MBytes
> [ 5] 1.00-2.00 sec 600 MBytes 5.03 Gbits/sec 0 1.61 MBytes
> [ 5] 2.00-3.01 sec 582 MBytes 4.85 Gbits/sec 0 1.61 MBytes
> [ 5] 3.01-4.01 sec 507 MBytes 4.26 Gbits/sec 0 1.61 MBytes
> [ 5] 4.01-5.01 sec 420 MBytes 3.53 Gbits/sec 0 1.61 MBytes
> [ 5] 5.01-6.01 sec 361 MBytes 3.03 Gbits/sec 0 1.61 MBytes
> [ 5] 6.01-7.00 sec 349 MBytes 2.94 Gbits/sec 0 1.61 MBytes
> [ 5] 7.00-8.00 sec 346 MBytes 2.91 Gbits/sec 0 1.61 MBytes
> [ 5] 8.00-9.00 sec 354 MBytes 2.96 Gbits/sec 0 1.61 MBytes
> [ 5] 9.00-10.00 sec 345 MBytes 2.90 Gbits/sec 0 1.61 MBytes
> - - - - - - - - - - - - - - - - - - - - - - - - -
> [ ID] Interval Transfer Bitrate Retr
> [ 5] 0.00-10.00 sec 4.11 GBytes 3.53 Gbits/sec 75 sender
> [ 5] 0.00-10.00 sec 4.11 GBytes 3.53 Gbits/sec receiver
>
> iperf Done.
> # iperf3 -c 192.168.200.10 -R
> Connecting to host 192.168.200.10, port 5201
> Reverse mode, remote host 192.168.200.10 is sending
> [ 5] local 192.168.100.10 port 10129 connected to 192.168.200.10 port 5201
> [ ID] Interval Transfer Bitrate
> [ 5] 0.00-1.01 sec 461 MBytes 3.84 Gbits/sec
> [ 5] 1.01-2.00 sec 453 MBytes 3.83 Gbits/sec
> [ 5] 2.00-3.00 sec 458 MBytes 3.83 Gbits/sec
> [ 5] 3.00-4.00 sec 451 MBytes 3.79 Gbits/sec
> [ 5] 4.00-5.00 sec 445 MBytes 3.74 Gbits/sec
> [ 5] 5.00-6.06 sec 477 MBytes 3.77 Gbits/sec
> [ 5] 6.06-7.00 sec 427 MBytes 3.81 Gbits/sec
> [ 5] 7.00-8.00 sec 449 MBytes 3.78 Gbits/sec
> [ 5] 8.00-9.04 sec 467 MBytes 3.78 Gbits/sec
> [ 5] 9.04-10.00 sec 436 MBytes 3.80 Gbits/sec
> - - - - - - - - - - - - - - - - - - - - - - - - -
> [ ID] Interval Transfer Bitrate Retr
> [ 5] 0.00-10.00 sec 4.42 GBytes 3.80 Gbits/sec 0 sender
> [ 5] 0.00-10.00 sec 4.42 GBytes 3.80 Gbits/sec receiver
>
> iperf Done.
> ```
>
> I will look into more deeper what's happening on my OpenBSD kernel.
I found that the number of ACKs returned slows down the TCP bulk transfer.
I'm using FreeBSD hosts for iperf3 client and server. The FreeBSD kernel
returns ACK packets for every 2 packets received. It will be a larger number
of ACKs. While the OpenBSD kernel is forwarding bulk TCP packets, it
receives a lot of ACK packets. The source and destination address and
the port number of ACK packets are swapped, but the same values, so that
the RSS hash value will be the same. The bulk TCP input interface and
the ACK input interface are different, but the same queue number is
interrupted by the RSS. So the same softnet taskqueue is used. This means
that while transferring the bulk TCP packets, ACK packets are delayed and
vice versa. The delay of ACK packets slows down the sliding window of bulk
TCP stream and won't reach 10Gbps speed.
One solution of this issue is reducing the number of ACK packets from
the FreeBSD kernel. I set LRO option in the iperf3 server interface (I'm
using X520 nics for the FreeBSD host). The LRO feature merges received TCP
packets of the same stream, the number of packets received for the FreeBSD
kernel will be reduced, so that the number of ACKs returned will be reduced.
I've got the following transfer performance with LRO option. The OpenBSD
kernel transfers a 10Gbps TCP stream.
```
# iperf3 -c 192.168.200.10
Connecting to host 192.168.200.10, port 5201
[ 5] local 192.168.100.10 port 19855 connected to 192.168.200.10 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.06 sec 381 MBytes 3.00 Gbits/sec 26 1.07 MBytes
[ 5] 1.06-2.06 sec 912 MBytes 7.68 Gbits/sec 37 1.44 MBytes
[ 5] 2.06-3.06 sec 1.10 GBytes 9.41 Gbits/sec 0 1.60 MBytes
[ 5] 3.06-4.00 sec 1.03 GBytes 9.41 Gbits/sec 0 1.60 MBytes
[ 5] 4.00-5.06 sec 1.16 GBytes 9.41 Gbits/sec 0 1.60 MBytes
[ 5] 5.06-6.03 sec 1.05 GBytes 9.41 Gbits/sec 0 1.61 MBytes
[ 5] 6.03-7.06 sec 1.14 GBytes 9.41 Gbits/sec 0 1.61 MBytes
[ 5] 7.06-8.00 sec 1.03 GBytes 9.42 Gbits/sec 0 1.61 MBytes
[ 5] 8.00-9.01 sec 1.10 GBytes 9.41 Gbits/sec 0 1.61 MBytes
[ 5] 9.01-10.00 sec 1.09 GBytes 9.41 Gbits/sec 0 1.61 MBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 9.97 GBytes 8.56 Gbits/sec 63 sender
[ 5] 0.00-10.00 sec 9.97 GBytes 8.56 Gbits/sec receiver
iperf Done.
```
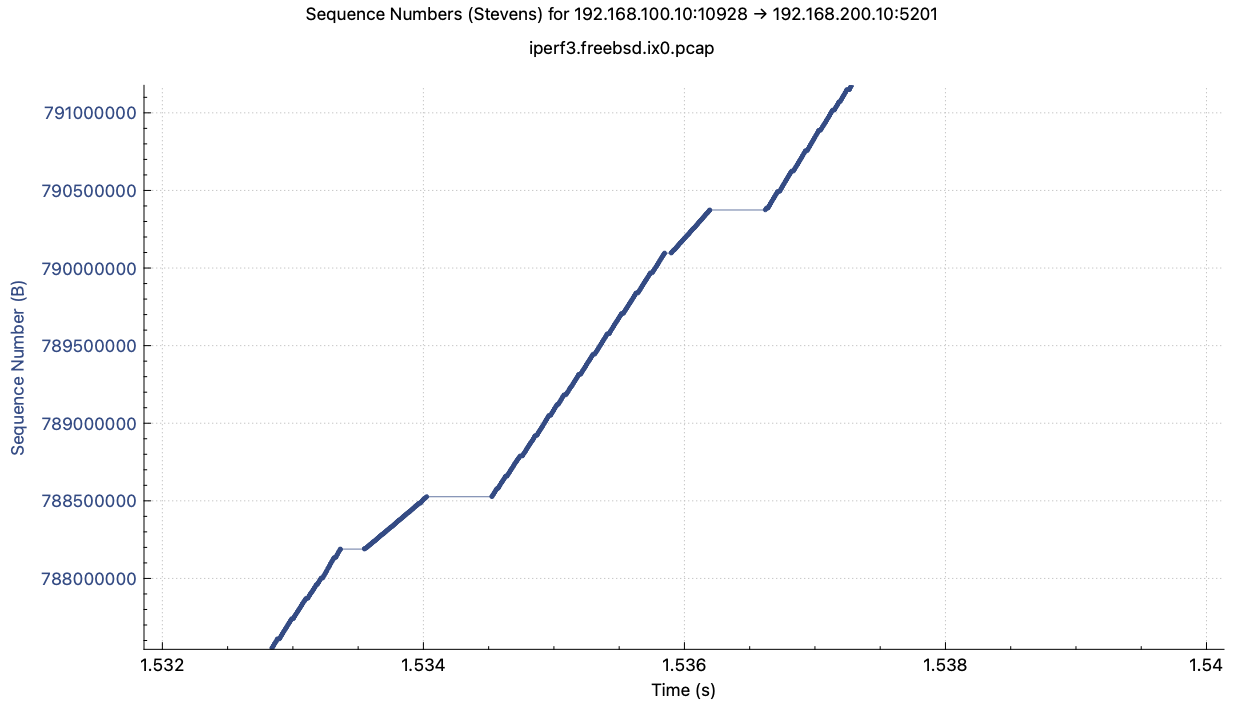
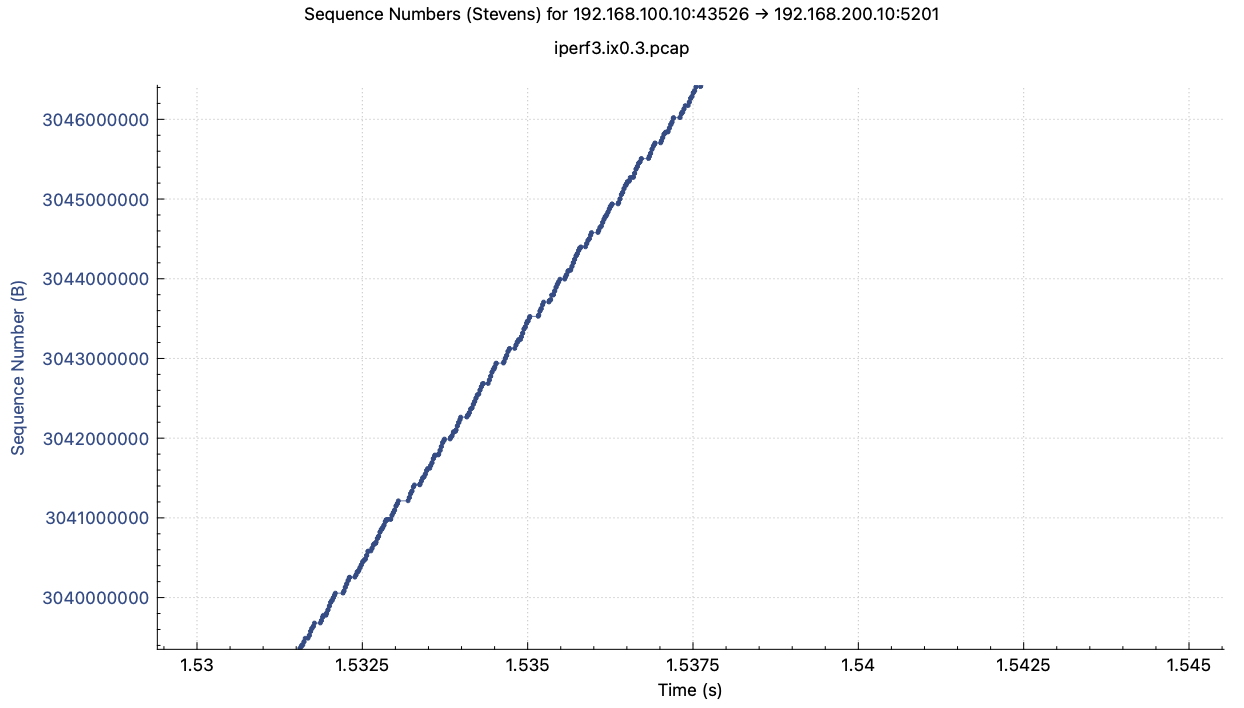
I captured bulk TCP packets with LRO and without LRO cases and drew TCP
sequence number graphs. The 'without_lro.png' shows that TCP sequence
number increment sometimes delays. It happens on receiving a lot of ACK
packets. The 'with_lro.png' doesn't show such a kind of delay as the same
zoom level.
Conclusion: This slow TCP transfer issue doesn't relate to the SoftLRO patch.
The SoftLRO patch works as intended and also works nicely to me.
>>
>> Further tests and comments are welcome.
>>
>> Thanks,
>> Jan
>>
>> Index: arch/octeon/dev/if_cnmac.c
>> ===================================================================
>> RCS file: /cvs/src/sys/arch/octeon/dev/if_cnmac.c,v
>> diff -u -p -r1.86 if_cnmac.c
>> --- arch/octeon/dev/if_cnmac.c 20 May 2024 23:13:33 -0000 1.86
>> +++ arch/octeon/dev/if_cnmac.c 4 Mar 2025 14:53:49 -0000
>> @@ -55,6 +55,9 @@
>> #include <net/if_media.h>
>> #include <netinet/in.h>
>> #include <netinet/if_ether.h>
>> +#include <netinet/tcp.h>
>> +#include <netinet/tcp_timer.h>
>> +#include <netinet/tcp_var.h>
>>
>> #if NBPFILTER > 0
>> #include <net/bpf.h>
>> @@ -306,7 +309,7 @@ cnmac_attach(struct device *parent, stru
>> strncpy(ifp->if_xname, sc->sc_dev.dv_xname, sizeof(ifp->if_xname));
>> ifp->if_softc = sc;
>> ifp->if_flags = IFF_BROADCAST | IFF_SIMPLEX | IFF_MULTICAST;
>> - ifp->if_xflags = IFXF_MPSAFE;
>> + ifp->if_xflags = IFXF_MPSAFE | IFXF_LRO;
>> ifp->if_ioctl = cnmac_ioctl;
>> ifp->if_qstart = cnmac_start;
>> ifp->if_watchdog = cnmac_watchdog;
>> @@ -314,7 +317,7 @@ cnmac_attach(struct device *parent, stru
>> ifq_init_maxlen(&ifp->if_snd, max(GATHER_QUEUE_SIZE, IFQ_MAXLEN));
>>
>> ifp->if_capabilities = IFCAP_VLAN_MTU | IFCAP_CSUM_TCPv4 |
>> - IFCAP_CSUM_UDPv4 | IFCAP_CSUM_TCPv6 | IFCAP_CSUM_UDPv6;
>> + IFCAP_CSUM_UDPv4 | IFCAP_CSUM_TCPv6 | IFCAP_CSUM_UDPv6 | IFCAP_LRO;
>>
>> cn30xxgmx_set_filter(sc->sc_gmx_port);
>>
>> @@ -1246,7 +1249,7 @@ cnmac_recv(struct cnmac_softc *sc, uint6
>> M_TCP_CSUM_IN_OK | M_UDP_CSUM_IN_OK;
>> }
>>
>> - ml_enqueue(ml, m);
>> + tcp_softlro_enqueue(ifp, ml, m);
>>
>> return nmbuf;
>>
>> Index: dev/pci/if_bnxt.c
>> ===================================================================
>> RCS file: /cvs/src/sys/dev/pci/if_bnxt.c,v
>> diff -u -p -r1.52 if_bnxt.c
>> --- dev/pci/if_bnxt.c 6 Oct 2024 23:43:18 -0000 1.52
>> +++ dev/pci/if_bnxt.c 4 Mar 2025 14:53:48 -0000
>> @@ -646,6 +646,8 @@ bnxt_attach(struct device *parent, struc
>> IFCAP_CSUM_UDPv4 | IFCAP_CSUM_TCPv4 | IFCAP_CSUM_UDPv6 |
>> IFCAP_CSUM_TCPv6;
>> ifp->if_capabilities |= IFCAP_TSOv4 | IFCAP_TSOv6;
>> + ifp->if_xflags |= IFXF_LRO;
>> + ifp->if_capabilities |= IFCAP_LRO;
>> #if NVLAN > 0
>> ifp->if_capabilities |= IFCAP_VLAN_HWTAGGING;
>> #endif
>> @@ -2283,6 +2285,7 @@ bnxt_rx(struct bnxt_softc *sc, struct bn
>> struct bnxt_cp_ring *cpr, struct mbuf_list *ml, int *slots, int *agslots,
>> struct cmpl_base *cmpl)
>> {
>> + struct ifnet *ifp = &sc->sc_ac.ac_if;
>> struct mbuf *m, *am;
>> struct bnxt_slot *bs;
>> struct rx_pkt_cmpl *rxlo = (struct rx_pkt_cmpl *)cmpl;
>> @@ -2355,7 +2358,7 @@ bnxt_rx(struct bnxt_softc *sc, struct bn
>> (*agslots)++;
>> }
>>
>> - ml_enqueue(ml, m);
>> + tcp_softlro_enqueue(ifp, ml, m);
>> return (0);
>> }
>>
>> Index: dev/pci/if_em.c
>> ===================================================================
>> RCS file: /cvs/src/sys/dev/pci/if_em.c,v
>> diff -u -p -r1.378 if_em.c
>> --- dev/pci/if_em.c 31 Aug 2024 16:23:09 -0000 1.378
>> +++ dev/pci/if_em.c 4 Mar 2025 14:53:48 -0000
>> @@ -2013,6 +2013,9 @@ em_setup_interface(struct em_softc *sc)
>> ifp->if_capabilities |= IFCAP_TSOv4 | IFCAP_TSOv6;
>> }
>>
>> + ifp->if_xflags |= IFXF_LRO;
>> + ifp->if_capabilities |= IFCAP_LRO;
>> +
>> /*
>> * Specify the media types supported by this adapter and register
>> * callbacks to update media and link information
>> @@ -3185,7 +3188,8 @@ em_rxeof(struct em_queue *que)
>> m->m_flags |= M_VLANTAG;
>> }
>> #endif
>> - ml_enqueue(&ml, m);
>> +
>> + tcp_softlro_enqueue(ifp, &ml, m);
>>
>> que->rx.fmp = NULL;
>> que->rx.lmp = NULL;
>> Index: dev/pci/if_ixl.c
>> ===================================================================
>> RCS file: /cvs/src/sys/dev/pci/if_ixl.c,v
>> diff -u -p -r1.102 if_ixl.c
>> --- dev/pci/if_ixl.c 30 Oct 2024 18:02:45 -0000 1.102
>> +++ dev/pci/if_ixl.c 4 Mar 2025 14:53:49 -0000
>> @@ -883,6 +883,8 @@ struct ixl_rx_wb_desc_16 {
>>
>> #define IXL_RX_DESC_PTYPE_SHIFT 30
>> #define IXL_RX_DESC_PTYPE_MASK (0xffULL << IXL_RX_DESC_PTYPE_SHIFT)
>> +#define IXL_RX_DESC_PTYPE_MAC_IPV4_TCP 26
>> +#define IXL_RX_DESC_PTYPE_MAC_IPV6_TCP 92
>>
>> #define IXL_RX_DESC_PLEN_SHIFT 38
>> #define IXL_RX_DESC_PLEN_MASK (0x3fffULL << IXL_RX_DESC_PLEN_SHIFT)
>> @@ -1976,6 +1978,9 @@ ixl_attach(struct device *parent, struct
>> IFCAP_CSUM_TCPv6 | IFCAP_CSUM_UDPv6;
>> ifp->if_capabilities |= IFCAP_TSOv4 | IFCAP_TSOv6;
>>
>> + ifp->if_xflags |= IFXF_LRO;
>> + ifp->if_capabilities |= IFCAP_LRO;
>> +
>> ifmedia_init(&sc->sc_media, 0, ixl_media_change, ixl_media_status);
>>
>> ixl_media_add(sc, phy_types);
>> @@ -3255,9 +3260,11 @@ ixl_rxeof(struct ixl_softc *sc, struct i
>> struct ixl_rx_map *rxm;
>> bus_dmamap_t map;
>> unsigned int cons, prod;
>> - struct mbuf_list ml = MBUF_LIST_INITIALIZER();
>> + struct mbuf_list mlt = MBUF_LIST_INITIALIZER();
>> + struct mbuf_list mlo = MBUF_LIST_INITIALIZER();
>> struct mbuf *m;
>> uint64_t word;
>> + unsigned int ptype;
>> unsigned int len;
>> unsigned int mask;
>> int done = 0;
>> @@ -3294,6 +3301,8 @@ ixl_rxeof(struct ixl_softc *sc, struct i
>> m = rxm->rxm_m;
>> rxm->rxm_m = NULL;
>>
>> + ptype = (word & IXL_RX_DESC_PTYPE_MASK)
>> + >> IXL_RX_DESC_PTYPE_SHIFT;
>> len = (word & IXL_RX_DESC_PLEN_MASK) >> IXL_RX_DESC_PLEN_SHIFT;
>> m->m_len = len;
>> m->m_pkthdr.len = 0;
>> @@ -3324,7 +3333,12 @@ ixl_rxeof(struct ixl_softc *sc, struct i
>> #endif
>>
>> ixl_rx_checksum(m, word);
>> - ml_enqueue(&ml, m);
>> +
>> + if (ptype == IXL_RX_DESC_PTYPE_MAC_IPV4_TCP ||
>> + ptype == IXL_RX_DESC_PTYPE_MAC_IPV6_TCP)
>> + tcp_softlro_enqueue(ifp, &mlt, m);
>> + else
>> + ml_enqueue(&mlo, m);
>> } else {
>> ifp->if_ierrors++; /* XXX */
>> m_freem(m);
>> @@ -3342,7 +3356,7 @@ ixl_rxeof(struct ixl_softc *sc, struct i
>>
>> if (done) {
>> rxr->rxr_cons = cons;
>> - if (ifiq_input(ifiq, &ml))
>> + if (ifiq_input(ifiq, &mlt) || ifiq_input(ifiq, &mlo))
>> if_rxr_livelocked(&rxr->rxr_acct);
>> ixl_rxfill(sc, rxr);
>> }
>> Index: net/if.c
>> ===================================================================
>> RCS file: /cvs/src/sys/net/if.c,v
>> diff -u -p -r1.728 if.c
>> --- net/if.c 2 Mar 2025 21:28:31 -0000 1.728
>> +++ net/if.c 4 Mar 2025 14:53:49 -0000
>> @@ -3388,6 +3388,7 @@ ifsetlro(struct ifnet *ifp, int on)
>> } else if (!on && ISSET(ifp->if_xflags, IFXF_LRO))
>> CLR(ifp->if_xflags, IFXF_LRO);
>>
>> + error = 0;
>> out:
>> splx(s);
>>
>> Index: netinet/tcp_input.c
>> ===================================================================
>> RCS file: /cvs/src/sys/netinet/tcp_input.c,v
>> diff -u -p -r1.433 tcp_input.c
>> --- netinet/tcp_input.c 2 Mar 2025 21:28:32 -0000 1.433
>> +++ netinet/tcp_input.c 4 Mar 2025 15:07:04 -0000
>> @@ -84,6 +84,7 @@
>> #include <net/if_var.h>
>> #include <net/route.h>
>>
>> +#include <netinet/if_ether.h>
>> #include <netinet/in.h>
>> #include <netinet/ip.h>
>> #include <netinet/in_pcb.h>
>> @@ -4229,4 +4230,233 @@ syn_cache_respond(struct syn_cache *sc,
>> }
>> in_pcbunref(inp);
>> return (error);
>> +}
>> +
>> +int
>> +tcp_softlro(struct mbuf *mhead, struct mbuf *mtail)
>> +{
>> + struct ether_extracted head;
>> + struct ether_extracted tail;
>> + struct mbuf *m;
>> + unsigned int hdrlen;
>> +
>> + /*
>> + * Check if head and tail are mergeable
>> + */
>> +
>> + ether_extract_headers(mhead, &head);
>> + ether_extract_headers(mtail, &tail);
>> +
>> + /* Don't merge packets of different VLANs */
>> + if (head.evh && tail.evh) {
>> + if (head.evh->evl_tag != tail.evh->evl_tag)
>> + return 0;
>> + } else if (head.evh || tail.evh)
>> + return 0;
>> +
>> + /* Check IP header. */
>> + if (head.ip4 && tail.ip4) {
>> + /* Don't merge packets with invalid header checksum. */
>> + if (!ISSET(mhead->m_pkthdr.csum_flags, M_IPV4_CSUM_IN_OK) ||
>> + !ISSET(mtail->m_pkthdr.csum_flags, M_IPV4_CSUM_IN_OK))
>> + return 0;
>> +
>> + /* Check IPv4 addresses. */
>> + if (head.ip4->ip_src.s_addr != tail.ip4->ip_src.s_addr ||
>> + head.ip4->ip_dst.s_addr != tail.ip4->ip_dst.s_addr)
>> + return 0;
>> +
>> + /* Don't merge IPv4 fragments. */
>> + if (ISSET(head.ip4->ip_off, htons(IP_OFFMASK | IP_MF)) ||
>> + ISSET(tail.ip4->ip_off, htons(IP_OFFMASK | IP_MF)))
>> + return 0;
>> +
>> + /* Check max. IPv4 length. */
>> + if (head.iplen + tail.iplen > IP_MAXPACKET)
>> + return 0;
>> +
>> + /* Don't merge IPv4 packets with option headers. */
>> + if (head.iphlen != sizeof(struct ip) ||
>> + tail.iphlen != sizeof(struct ip))
>> + return 0;
>> +
>> + /* Don't non-TCP packets. */
>> + if (head.ip4->ip_p != IPPROTO_TCP ||
>> + tail.ip4->ip_p != IPPROTO_TCP)
>> + return 0;
>> + } else if (head.ip6 && tail.ip6) {
>> + /* Check IPv6 addresses. */
>> + if (!IN6_ARE_ADDR_EQUAL(&head.ip6->ip6_src, &tail.ip6->ip6_src) ||
>> + !IN6_ARE_ADDR_EQUAL(&head.ip6->ip6_dst, &tail.ip6->ip6_dst))
>> + return 0;
>> +
>> + /* Check max. IPv6 length. */
>> + if ((head.iplen - head.iphlen) +
>> + (tail.iplen - tail.iphlen) > IPV6_MAXPACKET)
>> + return 0;
>> +
>> + /* Don't merge IPv6 packets with option headers nor non-TCP. */
>> + if (head.ip6->ip6_nxt != IPPROTO_TCP ||
>> + tail.ip6->ip6_nxt != IPPROTO_TCP)
>> + return 0;
>> + } else {
>> + return 0;
>> + }
>> +
>> + /* Check TCP header. */
>> + if (!head.tcp || !tail.tcp)
>> + return 0;
>> +
>> + /* Check TCP ports. */
>> + if (head.tcp->th_sport != tail.tcp->th_sport ||
>> + head.tcp->th_dport != tail.tcp->th_dport)
>> + return 0;
>> +
>> + /* Don't merge empty segments. */
>> + if (head.paylen == 0 || tail.paylen == 0)
>> + return 0;
>> +
>> + /* Check for continues segments. */
>> + if (ntohl(head.tcp->th_seq) + head.paylen != ntohl(tail.tcp->th_seq))
>> + return 0;
>> +
>> + /* Just ACK and PUSH TCP flags are allowed. */
>> + if (ISSET(head.tcp->th_flags, ~(TH_ACK|TH_PUSH)) ||
>> + ISSET(tail.tcp->th_flags, ~(TH_ACK|TH_PUSH)))
>> + return 0;
>> +
>> + /* TCP ACK flag has to be set. */
>> + if (!ISSET(head.tcp->th_flags, TH_ACK) ||
>> + !ISSET(tail.tcp->th_flags, TH_ACK))
>> + return 0;
>> +
>> + /* Ignore segments with different TCP options. */
>> + if (head.tcphlen - sizeof(struct tcphdr) !=
>> + tail.tcphlen - sizeof(struct tcphdr))
>> + return 0;
>> +
>> + /* Check for TCP options */
>> + if (head.tcphlen > sizeof(struct tcphdr)) {
>> + char *hopt = (char *)(head.tcp) + sizeof(struct tcphdr);
>> + char *topt = (char *)(tail.tcp) + sizeof(struct tcphdr);
>> + int optsize = head.tcphlen - sizeof(struct tcphdr);
>> + int optlen;
>> +
>> + for (; optsize > 0; optsize -= optlen) {
>> + /* Ignore segments with different TCP options. */
>> + if (hopt[0] != topt[0] || hopt[1] != topt[1])
>> + return 0;
>> +
>> + /* Get option length */
>> + optlen = hopt[1];
>> + if (hopt[0] == TCPOPT_NOP)
>> + optlen = 1;
>> + else if (optlen < 2 || optlen > optsize)
>> + return 0; /* Illegal length */
>> +
>> + if (hopt[0] != TCPOPT_NOP &&
>> + hopt[0] != TCPOPT_TIMESTAMP)
>> + return 0; /* Unsupported TCP option */
>> +
>> + hopt += optlen;
>> + topt += optlen;
>> + }
>> + }
>> +
>> + /*
>> + * Prepare concatenation of head and tail.
>> + */
>> +
>> + /* Adjust IP header. */
>> + if (head.ip4) {
>> + head.ip4->ip_len = htons(head.iplen + tail.paylen);
>> + } else if (head.ip6) {
>> + head.ip6->ip6_plen =
>> + htons(head.iplen - head.iphlen + tail.paylen);
>> + }
>> +
>> + /* Combine TCP flags from head and tail. */
>> + if (ISSET(tail.tcp->th_flags, TH_PUSH))
>> + SET(head.tcp->th_flags, TH_PUSH);
>> +
>> + /* Adjust TCP header. */
>> + head.tcp->th_win = tail.tcp->th_win;
>> + head.tcp->th_ack = tail.tcp->th_ack;
>> +
>> + /* Calculate header length of tail packet. */
>> + hdrlen = sizeof(*tail.eh);
>> + if (tail.evh)
>> + hdrlen = sizeof(*tail.evh);
>> + hdrlen += tail.iphlen;
>> + hdrlen += tail.tcphlen;
>> +
>> + /* Skip protocol headers in tail. */
>> + m_adj(mtail, hdrlen);
>> + CLR(mtail->m_flags, M_PKTHDR);
>> +
>> + /* Concatenate */
>> + for (m = mhead; m->m_next;)
>> + m = m->m_next;
>> + m->m_next = mtail;
>> + mhead->m_pkthdr.len += tail.paylen;
>> +
>> + /* Flag mbuf as TSO packet with MSS. */
>> + if (!ISSET(mhead->m_pkthdr.csum_flags, M_TCP_TSO)) {
>> + /* Set CSUM_OUT flags in case of forwarding. */
>> + SET(mhead->m_pkthdr.csum_flags, M_TCP_CSUM_OUT);
>> + head.tcp->th_sum = 0;
>> + if (head.ip4) {
>> + SET(mhead->m_pkthdr.csum_flags, M_IPV4_CSUM_OUT);
>> + head.ip4->ip_sum = 0;
>> + }
>> +
>> + SET(mhead->m_pkthdr.csum_flags, M_TCP_TSO);
>> + mhead->m_pkthdr.ph_mss = head.paylen;
>> + tcpstat_inc(tcps_inhwlro);
>> + tcpstat_inc(tcps_inpktlro); /* count head */
>> + }
>> + mhead->m_pkthdr.ph_mss = MAX(mhead->m_pkthdr.ph_mss, tail.paylen);
>> + tcpstat_inc(tcps_inpktlro); /* count tail */
>> +
>> + return 1;
>> +}
>> +
>> +void
>> +tcp_softlro_enqueue(struct ifnet *ifp, struct mbuf_list *ml, struct mbuf *mtail)
>> +{
>> + struct mbuf *mhead;
>> +
>> + if (!ISSET(ifp->if_xflags, IFXF_LRO))
>> + goto out;
>> +
>> + /* Don't merge packets with invalid header checksum. */
>> + if (!ISSET(mtail->m_pkthdr.csum_flags, M_TCP_CSUM_IN_OK))
>> + goto out;
>> +
>> + for (mhead = ml->ml_head; mhead != NULL; mhead = mhead->m_nextpkt) {
>> + /* Don't merge packets with invalid header checksum. */
>> + if (!ISSET(mhead->m_pkthdr.csum_flags, M_TCP_CSUM_IN_OK))
>> + continue;
>> +
>> + /* Use RSS hash to skip packets of different connections. */
>> + if (ISSET(mhead->m_pkthdr.csum_flags, M_FLOWID) &&
>> + ISSET(mtail->m_pkthdr.csum_flags, M_FLOWID) &&
>> + mhead->m_pkthdr.ph_flowid != mtail->m_pkthdr.ph_flowid)
>> + continue;
>> +
>> + /* Don't merge packets of different VLANs */
>> + if (ISSET(mhead->m_flags, M_VLANTAG) !=
>> + ISSET(mtail->m_flags, M_VLANTAG))
>> + continue;
>> +
>> + if (ISSET(mhead->m_flags, M_VLANTAG) &&
>> + EVL_VLANOFTAG(mhead->m_pkthdr.ether_vtag) !=
>> + EVL_VLANOFTAG(mtail->m_pkthdr.ether_vtag))
>> + continue;
>> +
>> + if (tcp_softlro(mhead, mtail))
>> + return;
>> + }
>> + out:
>> + ml_enqueue(ml, mtail);
>> }
>> Index: netinet/tcp_var.h
>> ===================================================================
>> RCS file: /cvs/src/sys/netinet/tcp_var.h,v
>> diff -u -p -r1.186 tcp_var.h
>> --- netinet/tcp_var.h 2 Mar 2025 21:28:32 -0000 1.186
>> +++ netinet/tcp_var.h 4 Mar 2025 14:53:48 -0000
>> @@ -720,6 +720,7 @@ void tcp_init(void);
>> int tcp_input(struct mbuf **, int *, int, int, struct netstack *);
>> int tcp_mss(struct tcpcb *, int);
>> void tcp_mss_update(struct tcpcb *);
>> +void tcp_softlro_enqueue(struct ifnet *, struct mbuf_list *, struct mbuf *);
>> u_int tcp_hdrsz(struct tcpcb *);
>> void tcp_mtudisc(struct inpcb *, int);
>> void tcp_mtudisc_increase(struct inpcb *, int);
>
> --
> Yuichiro NAITO (naito.yuichiro@gmail.com)
--
Yuichiro NAITO (naito.yuichiro@gmail.com)
SoftLRO for ixl(4), bnxt(4) and em(4)
{kind=link}
{kind=link}